
10 CRO Experts Explain How To Profitably Analyze AB Test Results
The AB test results had come in, and the result was inconclusive. The Conversion Sciences team was disappointed. They thought the change would increase revenue. What they didn’t know what that the top-level results were lying.
While we can learn something from inconclusive tests, it’s the winners that we love. Winners increase revenue, and that feels good.
The team looked closer at our results. When a test concludes, we analyze the results in analytics to see if there is any more we can learn. We call this post-test analysis.
Isolating the segment of traffic that saw test variation A, it was clear that one browser had under-performed the others: Internet Explorer.

Performance of Variation A. Internet Explorer visitors significantly under-performed the other three popular browsers.
The visitors coming on Internet Explorer were converting at less than half the average of the other browsers and generating one-third the revenue per session. This was not true of the Control. Something was wrong with this test variation. Despite a vigorous QA effort that included all popular browsers, an error had been introduced into the test code.
Analysis showed that correcting this would deliver a 13% increase in conversion rate and 19% increase in per session value. And we would have a winning test after all.
Conversion Sciences has a rigorous QA process to ensure that errors like this are very rare, but they happen. And they may be happening to you.
Post-test analysis keeps us from making bad decisions when the unexpected rears its ugly head. Here’s a primer on how conversion experts ensure they are making the right decisions by doing post-test analysis.
Did Any Of Our Test Variations Win?
The first question that will be on our lips is, “Did any of our variations win?”
There are two possible outcomes when we examine the results of an AB test.
- The test was inconclusive. None of the alternatives beat the control. The null hypotheses was not disproven.
- One or more of the treatments beat the control in a statistically significant way.
Joel Harvey of Conversion Sciences describes his process below:
 Joel Harvey, Conversion Sciences
Joel Harvey, Conversion Sciences
“Post-test analysis” is sort of a misnomer. A lot of analytics happens in the initial setup and throughout full ab testing process. The “post-test” insights derived from one batch of tests is the “pre-test” analytics for the next batch, and the best way to have good goals for that next batch of tests is to set the right goals during your previous split tests.
That said, when you look at the results of an AB testing round, the first thing you need to look at is whether the test was a loser, a winner, or inconclusive.
Verify that the winners were indeed winners. Look at all the core criteria: statistical significance, p-value, test length, delta size, etc. If it checks out, then the next step is to show it to 100% of traffic and look for that real-world conversion lift.
In a perfect world you could just roll it out for 2 weeks and wait, but usually, you are jumping right into creating new hypotheses and running new tests, so you have to find a balance.
Once we’ve identified the winners, it’s important to dive into segments.
- Mobile versus non-mobile
- Paid versus unpaid
- Different browsers and devices
- Different traffic channels
- New versus returning visitors (important to setup and integrate this beforehand)
This is fairly easy to do with enterprise tools, but might require some more effort with less robust testing tools. It’s important to have a deep understanding of how tested pages performed with each segment. What’s the bounce rate? What’s the exit rate? Did we fundamentally change the way this segment is flowing through the funnel?
We want to look at this data in full, but it’s also good to remove outliers falling outside two standard deviations of the mean and re-evaluate the data.
It’s also important to pay attention to lead quality. The longer the lead cycle, the more difficult this is. In a perfect world, you can integrate the CRM, but in reality, this often doesn’t work very seamlessly.
Chris McCormick, Head of Optimisation at PRWD, describes his process:
 Chris McCormick, PRWD
Chris McCormick, PRWD
When a test concludes, we always use the testing tool as a guide but we would never hang our hat on that data. We always analyse results further within Google Analytics, as this is the purest form of data.
For any test, we always set out at the start what our ‘primary success metrics’ are. These are what we look to identify first via GA and what we communicate as a priority to the client. Once we have a high level understanding of how the test has performed, we start to dig below the surface to understand if there are any patterns or trends occurring. Examples of this would be: the day of the week, different product sets, new vs returning users, desktop vs mobile etc.
We always look to report on a rough ROI figure for any test we deliver, too. In most cases, I would look to do this based on taking data from the previous 12 months and applying whatever the lift was to that. This is always communicated to the client as a ballpark figure i.e.: circa £50k ROI. The reason for this is that there are so many additional/external influences on a test that we can never be 100% accurate; testing is not an exact science and shouldn’t be treated as such.
Are We Making Type I or Type II errors?
In our post on AB testing statistics, we discussed type I and type II errors. We work to avoid these errors at all cost.
To avoid errors in judgement, we verify the results of our testing tool against our analytics. It is very important that our testing tool send data to our analytics package telling us which variations are seen by which segments of visitors.
Our testing tools only deliver top-level results, and we’ve seen that technical errors happen. So we can reproduce the results of our AB test using analytics data.
Did each variation get the same number of conversions? Was revenue reported accurately?
Errors are best avoided by ensuring the sample size is large enough and utilizing a proper AB testing framework. Peep Laja describes his process below:
 Peep Laja, ConversionXL
Peep Laja, ConversionXL
First of all I check whether there’s enough sample size and that we can trust the outcome of the test. I check if the numbers reported by the testing tool line up with the analytics tool, both for CR (conversion rate) and RPV (revenue per visit).
In the analytics tool I try to understand how the variations changed user behavior – by looking at microconversions (cart adds, certain page visits etc) and other stats like cart value, average qty per purchase etc.
If the sample size is large enough, I want to see the results of the test across key segments (provided that the results in the segments are valid, have enough volume etc), and see if the treatments performed better/worse inside the segments. Maybe there’s a case for personalization there. The segments I look at are device split (if the test was ran across multiple device categories), new/returning, traffic source, first time buyer / repeat buyer.
How Did Key Segments Perform?
In the case of an inconclusive test, we want to look at individual segments of traffic.
For example, we have had an inconclusive test on smartphone traffic in which the Android visitors loved our variation, but iOS visitors hated it. They cancelled each other out. Yet we would have missed an important piece of information had we not looked more closely.
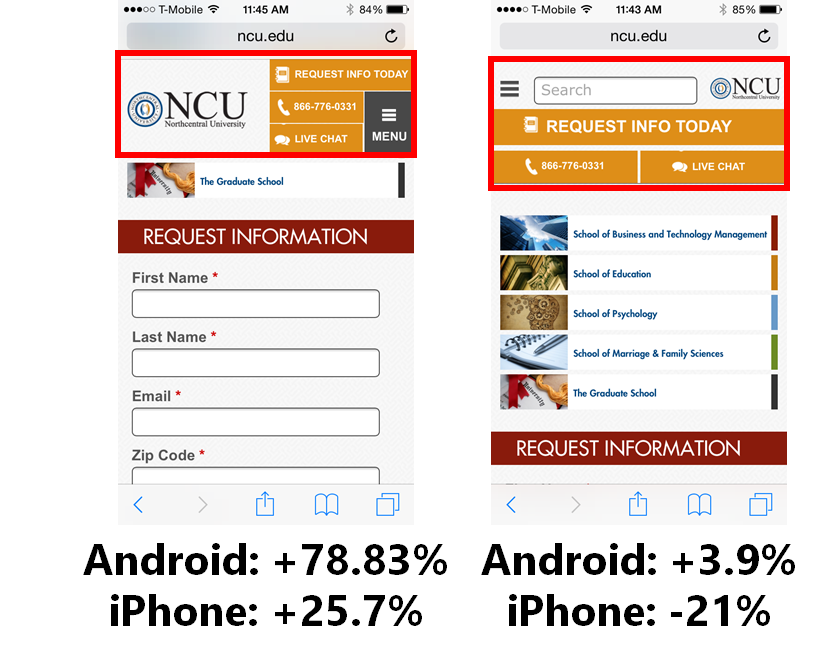
Visitors react differently depending on their device, browser and operating system.
Other segments that may perform differently may include:
- Return visitors vs. New visitors
- Chrome browsers vs. Safari browsers vs. Internet Explorer vs. …
- Organic traffic vs. paid traffic vs. referral traffic
- Email traffic vs. social media traffic
- Buyers of premium products vs. non-premium buyers
- Home page visitors vs. internal entrants
These segments will be different for each business, but provide insights that spawn new hypotheses, or even provide ways to personalize the experience.
Understanding how different segments are behaving is fundamental to good testing analysis, but it’s also important to keep the main thing the main thing, as Rich Page explains:
 Rich Page, Website Optimizer
Rich Page, Website Optimizer
Avoid analysis paralysis. Don’t slice the results into too many segments or different analytics tools. You may often run into conflicting findings. Revenue should always be considered the best metric to pay attention to other than conversion rate, after all, what good is a result with a conversion lift if it doesn’t also increase revenue?
The key thing is not to throw out A/B tests that have inconclusive results, as this will happen quite often. This is a great opportunity to learn and create a better follow up A/B test. In particular you should gain visitor feedback regarding the page being A/B tested, and show them your variations – this helps reveal great insights into what they like and don’t like. Reviewing related visitor recordings and click maps also gives good insights.
Nick So of WiderFunnel talks about segments as well within his own process for AB test analysis:
 Nick So, WiderFunnel
Nick So, WiderFunnel
“Besides the standard click-through rate, funnel drop-off, and conversion rate reports for post-test analysis, most of the additional reports and segments I pull are very dependent on the business context of a website’s visitors and customers.
For an ecommerce site that does a lot of email marketing and has high return buyers, I look at the difference in source traffic as well as new versus returning visitors. Discrepancies in behavior between segments can provide insights for future strategies, where you may want to focus on the behaviors of a particular segment in order to get that additional lift.
Sometimes, just for my own personal geeky curiosity, I look into seemingly random metrics to see if there are any unexpected patterns. But be warned: it’s easy to get too deep into that rabbit hole of splicing and dicing the data every which way to find some sort of pattern.
For lead-gen and B2B companies, you definitely want to look at the full buyer cycle and LTV of your visitors in order to determine the true winner of any experiment. Time and time again, I have seen tests that successfully increase lead submissions, only to discover that the quality of the leads coming through is drastically lower; which could cost a business MORE money in funnelling sales resources to unqualified leads.
In terms of post-test results analysis and validation — besides whatever statistical method your testing tool uses — I always run results through WiderFunnel’s internal results calculator which utilizes bayesian statistics to provide the risk and reward potential of each test. This allows you to make a more informed business decision, rather than simply a win/loss, significant/not significant recommendation.”
In addition to understanding how tested changes impacted each segment, it’s also useful to understand where in the customer journey those changes had the greatest impact, as Benjamin Cozon describes:
 Benjamin Cozon, Uptilab
Benjamin Cozon, Uptilab
We need to consider that the end of the running phase of a test is actually the beginning of insight analysis.
Why is each variation delivering a particular conversion rate? In which cases are my variations making a difference, whether positive or negative? In order to better understand the answers to these questions, we always try to identify which user segments are the most elastic to the changes that were made.
One way we do it is by ventilating the data with session-based or user-based dimensions. Here is some of the dimension we use for almost every test:
- User type (new / returning)
- Prospect / new Client / returning client
- Acquisition channel
- Type of landing page
This type of ventilation helps us understand the impact of specific changes for users relative to their specific place in the customer journey. Having these additional insights also helps us build a strong knowledge base and communicate effectively throughout the organization.
Finally, while it is a great idea to have a rigorous quality assurance (QA) process for your tests, some may slip through the cracks. When you examine segments of your traffic, you may find one segment that performed very poorly. This may be a sign that the experience they saw was broken.
It is not unusual to see visitors using Internet Explorer crash and burn since developers abhor making customizations for that non-compliant browser.
How Did Changes Affect Lead Quality?
Post test analysis allows us to be sure that the quality of our conversions is high. It’s easy to increase conversions. But are these new conversions buying as much as the ones who saw the control?
Several of Conversion Sciences’ clients prizes phone calls and the company optimizes for them. Each week, the calls are examined to ensure the callers are qualified to buy and truly interested in a solution.
In post-test analysis, we can examine the average order value for each variation to see if buyers were buying as much as before.
We can look at the profit margins generated for the products purchased. If revenue per visit rose, did profit follow suit?
Marshall Downey of Build.com has some more ideas for us in the following instagraph infographic.

Revenue is often looked to as the pre-eminent judge of lead quality, but doing so comes with it’s own pitfalls, as Ben Jesson describes in his approach to AB test analysis.
 Ben Jesson, Conversion Rate Experts
Ben Jesson, Conversion Rate Experts
If a test doesn’t reach significance, we quickly move on to the next big idea. There are limited gains to be had from adding complexity by promoting narrow segments.
It can be priceless to run on-page surveys on the winning page, to identify opportunities for improving it further. Qualaroo and Hotjar are great for this.
Lead quality is important, and we like to tackle it from two sides. First, qualitatively: Does the challenger page do anything that is likely to reduce or increase the lead value? Second, quantitatively: How can we track leads through to the bank, so we can ensure that we’ve grown the bottom line?
You might expect that it’s better to measure revenue than to measure the number of orders. However, statistically speaking, this is often not true. A handful of random large orders can greatly skew the revenue figures. Some people recommend manually removing the outliers, but that only acknowledges the method’s intrinsic problem. How do you define outlier, and why aren’t we interested in them? If your challenger hasn’t done anything that is likely to affect the order size, then you can save time by using the number of conversions as the goal.
After every winning experiment, record the results in a database that’s segmented by industry sector, type of website, geographic location, and conversion goal. We have been doing this for a decade, and the value it brings to projects is priceless.
Analyze AB Test Results by Time and Geography
Conversion quality is important, and Theresa Baiocco takes this one step further.
 Theresa Baiocco, Conversion Max
Theresa Baiocco, Conversion Max
For lead gen companies with a primary conversion goal of a phone call, it’s not enough to optimize for quantity of calls; you have to track and improve call quality. And if you’re running paid ads to get those phone calls, you need to incorporate your cost to acquire a high-quality phone call, segmented by:
- Hour of day
- Day of week
- Ad position
- Geographic location, etc
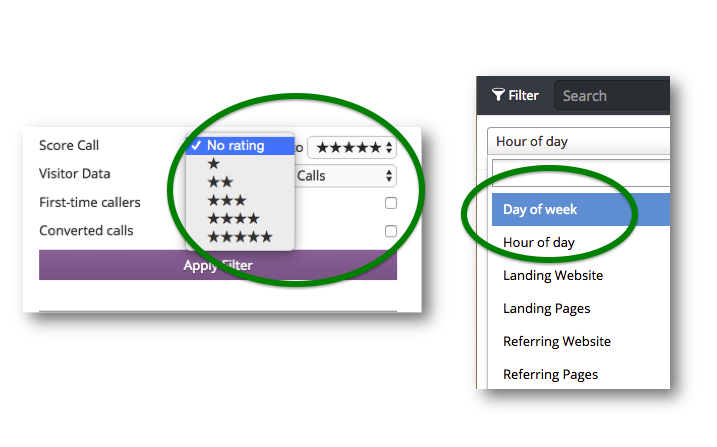
When testing for phone calls, you have to compare the data from your call tracking software with the data from your advertising. For example, if you want to know which day of the week your cost for a 5-star call is lowest, you first pull a report from your call tracking software on 5-star calls by day of week:
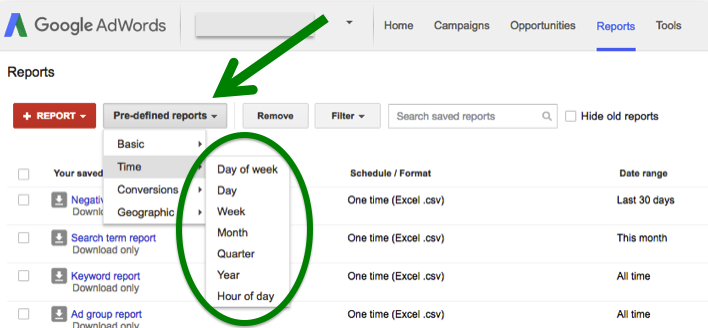
Then, check data from your advertising source, like Google AdWords. Pull a report of your cost by day of week for the same time period:
Then, you simply divide the amount you spent by the number of 5-star calls you got, to find out how much it costs to generate a 5-star call each day of the week.
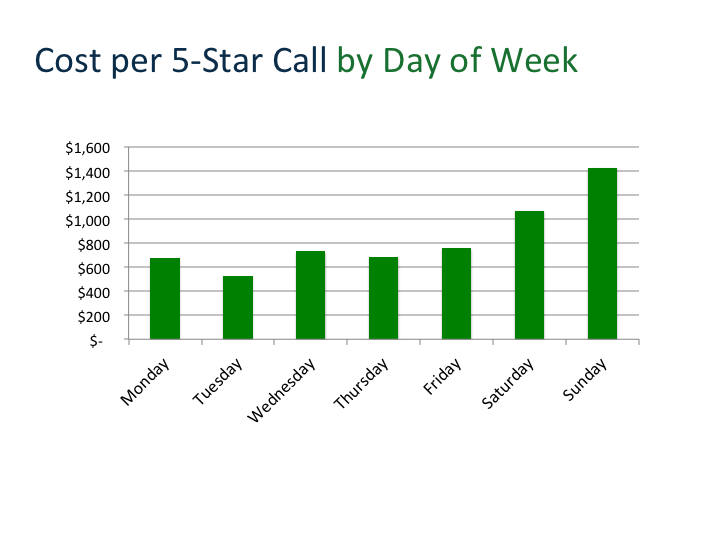
Repeat the process on other segments, such as hour of day, ad position, week of the month, geographic location, etc. By doing this extra analysis, you can shift your advertising budget to the days, times, and locations when you generate the highest quality of phone calls – for less.
Look for Unexpected Effects
Results aren’t derived in a vacuum. Any change will create ripple effects throughout a website, and some of these effects are easy to miss.
Craig Andrews gives us insight into this phenomenon via a recent discovery he made with a new client:
 Craig Andrews, allies4me
Craig Andrews, allies4me
I stumbled across something last week – and I almost missed it because it was secondary effects of a campaign I was running. One weakness of CRO, in my honest opinion, is the transactional focus of the practice. CRO doesn’t have a good way of measuring follow-on effects.
For example, I absolutely believe pop-ups increase conversions, but at what cost? How does it impact future engagement with the brand? If you are selling commodities, then it probably isn’t a big concern. But most people want to build brand trust & brand loyalty.
We discovered a shocking level of re-engagement with content based on the quality of a visitor’s first engagement. I probably wouldn’t believe it if I hadn’t seen it personally and double-checked the analytics. In the process of doing some general reporting, we discovered that we radically increased the conversion rates of the 2 leading landing pages as secondary effects of the initial effort.
We launched a piece of content that we helped the client develop. It was a new client and the development of this content was a little painful with many iterations as everyone wanted to weigh in on it. One of our biggest challenges was getting the client to agree to change the voice & tone of the piece – to use shorter words & shorter sentences. They were used to writing in a particular way and were afraid that their prospects wouldn’t trust & respect them if they didn’t write in a highbrow academic way.
We completed the piece, created a landing page and promoted the piece primarily via email to their existing list. We didn’t promote any other piece of content all month. They had several pieces (with landing pages) that had been up all year.
It was a big success. It was the most downloaded piece of content for the entire year. It had more downloads in one month than any other piece had in total for the entire year. Actually, 28% more downloads than #2 which had been up since January.
But then, I discovered something else…
The next 2 most downloaded pieces of content spiked in October. In fact, 50% of the total year’s downloads for those pieces happened in October. I thought it may be a product of more traffic & more eyeballs. Yes that helped, but it was more than that. The conversion rates for those 2 landing pages increased 160% & 280% respectively!
We did nothing to those landing pages. We didn’t promote that content. We changed nothing except the quality of the first piece of content that we sent out in our email campaign.
Better writing increased the brand equity for this client and increased the demand for all other content.
Testing results can also be compared against an archive of past results, as Shanelle Mullin discusses here:
Shanelle Mullin, ConversionXL
 There are two benefits to archiving your old test results properly. The first is that you’ll have a clear performance trail, which is important for communicating with clients and stakeholders. The second is that you can use past learnings to develop better test ideas in the future and, essentially, foster evolutionary learning.
There are two benefits to archiving your old test results properly. The first is that you’ll have a clear performance trail, which is important for communicating with clients and stakeholders. The second is that you can use past learnings to develop better test ideas in the future and, essentially, foster evolutionary learning.
The clearer you can communicate the ROI of your testing program to stakeholders and clients, the better. It means more buy-in and bigger budgets.
You can archive your test results in a few different ways. Tools like Projects and Effective Experiments can help, but some people use plain ol’ Excel to archive their tests. There’s no single best way to do it.
What’s really important is the information you record. You should include: the experiment date, the audience / URL, screenshots, the hypothesis, the results, any validity factors to consider (e.g. a PR campaign was running, it was mid-December), a link to the experiment, a link to a CSV of the results, and insights gained.
Why Did We Get The Result We Got?
Ultimately, we want to answer the question, “Why?” Why did one variation win and what does it tell us about our visitors?
This is a collaborative process and speculative in nature. Asking why has two primary effects:
- It develops new hypotheses for testing
- It causes us to rearrange the hypothesis list based on new information
Our goal is to learn as we test, and asking “Why?” is the best way to cement our learnings.

21 Quick and Easy CRO Copywriting Hacks
Keep these proven copywriting hacks in mind to make your copy convert.
- 43 Pages with Examples
- Assumptive Phrasing
- "We" vs. "You"
- Pattern Interrupts
- The Power of Three
"*" indicates required fields

Expertise: conversion rate optimization, AB testing, marketing strategy, digital marketing, analytics, landing page design, computer programming, entrepreneurship
Speaking: IBM, Inbound, LeadsCon, Content Marketing World, Affiliate Summit, and more
Books and Training: Your Conversion Creation Equation, Video CRO, Marketing Videos that Convert, CRO Best Practices
As Seen On: ClickZ, Search Engine Land, Marketing Land, Conversion Sciences Blog, Intended Consequences podcast
Education: Texas A&M University, BS Computer Science and Management
- Your Ads Are Making Promises Your Landing Page Experience Doesn’t Keep - July 1, 2026
- Using AI to Generate Copy that Converts - June 15, 2026
- AI: Why Your Website is Now a Training Tool - February 5, 2026












Trackbacks & Pingbacks
[…] Here’s how Chris McCormick from PRWD explains the process: […]
[…] Here’s how Chris McCormick from PRWD explains the process: […]
[…] Here’s how Chris McCormick from PRWD explains the process: […]
[…] Here’s how Chris McCormick from PRWD explains the process: […]
[…] For a more in-depth look at post test analysis, including insights from the CRO industry’s foremost experts, click here: 10 CRO Experts Explain How To Profitably Analyze AB Test Results […]
Comments are closed.